Last tutorial was on Indexes in Teradata in which we covered Primary Index, Secondary Index and Join Index. What we saw was just a summary of all the Indexes.
This tutorial will help you in understanding Primary Index in a much clearer way. As we saw last time a Primary Index determines the distribution of the rows on the disks controlled AMPs. A primary index in Teradata in required for row distribution and storage.
Below image shows how the distribution takes place using the Primary Indexes:
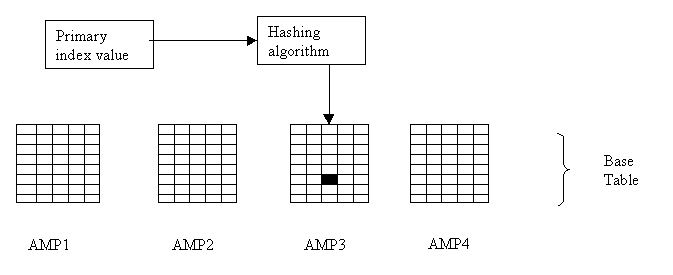
The PI for a table should represent the data values used by SQL to access the data for the table. Therefore, a PI for a table should be selected very carefully as it can improve or degrade the performance of SQL used for accessing that table.
Rules for Defining a PRIMARY INDEX
Below are some rules that I have come across while identifying on which column to be defined as PI:
* The PI selected should be such that it has unique index as more the unique index more evenly the rows will be distributed by the AMPs and better will be the space utilization.
* Define the index on as few columns as you can.
* The PI defined can have unique or non-unique values. If defined as unique then you will have to make sure that the each value you pass into the column is unique and never repeated whereas if defined non-unique you can pass duplicate values into that column.
* Flags and Junk Dimensions are never to be defined as PI as it leads to more skewness. Therefore that data in skewed and when you perform a join it can hamper the performance and lead to spool space error.
NOTE:
If you forget to define PRIMARY INDEX while doing a CREATE TABLE, the default will be use i.e. on the following:
* PRIMARY key
* First UNIQUE constraint
* First column
Creating PRIMARY INDEX
Unique primary index in created using the (UNIQUE) PRIMARY INDEX clause in the CREATE TABLE statement. Non-unique primary index are also created in the same way just removing the (UNIQUE) clause.
NOTE : Once a PRIMARY INDEX in created on TABLE it cannot be dropped or modified, the index must be changed by recreating the TABLE.
Example: Creating a UNIQUE PRIMARY INDEX
CREATE TABLE EMPLOYEE (EMP_ID INTEGER , EMP_NAME CHAR(15) , EMP_GRADE CHAR(1)) UNIQUE PRIMARY INDEX (EMP_ID);
Example: Creating a NON-UNIQUE PRIMARY INDEX
CREATE TABLE STUDENT (STUDENT_ID CHAR(15) , STUDENT_NAME CHAR(20) , DEPARTMENT CHAR(10)) PRIMARY INDEX (STUDENT_ID);
Data Access using PI
When a query contains a WHERE clause, and it has primary index value(s), the request in then processed by hashing the values to find the AMP where the row is stored and then the row which contains the same hash value in the RowID part of it is returned.
Primary Key vs Primary Index
I have seen many people who are working on Teradata still confuse between Primary Key and Primary Index. So here I have done a small comparison between both as both differ conceptually:
| Requirement | Not required, unless referential integrity checks are to be performed | Required |
| Defining | Define by CREATE TABLE statement | Defined by CREATE TABLE statement |
| Uniqueness | Unique | Unique or non-unique |
| Function | Identifies a row uniquely | Distributes rows |
| Values can be changed? | No | Yes |
| Can be null? | No | Yes |
| Related to access path? | No | Yes |
Hope this tutorial and the above short comparison helps everyone to understand what exactly PRIMARY INDEX is and how is should be chosen and defined. Do let me know your views about the post and help me in improving it.




